
为了提供实时分析,公司需要一个现代技术基础设施,包括这三点。
一个实时数据源,如网络点击流、传感器产生的物联网事件等。
一个平台,如ApacheKafka/Confluent,Spark或AmazonKinesis用于发布该事件数据流。
一个实时分析数据库,能够连续摄取大量的实时事件,并在几毫秒内返回查询结果。
事件流/流处理已经存在了近十年。它已被充分理解。而实时分析则不然。实时分析数据库的技术要求之一是可变性。可变性是一种超级能力,它能够对数据存储中的现有记录进行更新或变异。
可变和不可变数据之间的区别
在我们谈论为什么可变性是实时分析的关键之前,重要的是了解什么是可变性。
可变数据是指存储在表记录中的数据,可以被擦除或用更新的数据来更新。例如,在一个雇员地址的数据库中,假设每条记录都有个人的姓名和他们当前的居住地址。如果雇员从一个地方搬到另一个地方,当前的地址信息将被覆盖。
传统上,这些信息会被存储在交易型数据库中----。OracleDatabase,MySQL,PostgreSQL等--因为它们允许可变性。存储在这些交易型数据库中的任何字段都是可更新的。对于今天的实时分析,我们还有很多其他的原因需要可变性,包括数据的丰富性和回填数据。
不可变的数据则相反--它不能被删除或修改。更新不是写在现有的记录上,而是只做追加。这意味着更新被插入到不同的位置,或者你被迫重写新旧数据以正确存储它。稍后会有更多关于这个缺点的内容。不可变的数据存储在某些分析场景中是很有用的。
不变性的历史作用
数据仓库普及了不变性,因为它减轻了可扩展性,特别是在分布式系统中。分析性查询可以通过在RAM或SSD中缓存大量访问的只读数据来加速进行。如果缓存的数据是易变的,并且有可能发生变化,那么就必须不断地与原始数据进行核对,以避免变得陈旧或错误。这将增加数据仓库的操作复杂性;另一方面,不可变的数据则不会产生这样的问题。
不变性也减少了意外删除数据的风险,这在某些用例中是一个重要的好处。以医疗保健和病人健康记录为例。像新的医疗处方会被添加,而不是写在现有的或过期的处方上,这样你总是有一个完整的医疗记录。
最近,一些公司试图将Kafka和Kinesis等流发布系统与用于分析的不可变的数据仓库配对。这些事件系统捕获物联网和网络事件,并将其存储为日志文件。这些流式日志系统很难查询,所以人们通常会将日志中的所有数据发送到一个不可变的数据系统,如ApacheDruid来执行批量分析。
数据仓库将把新流的事件附加到现有的表格中。由于过去的事件在理论上是不会改变的,因此不可更改地存储数据似乎是一个正确的技术决定。虽然一个不可变的数据仓库只能按顺序写入数据,但它确实支持随机数据读取。这使得分析性商业应用能够有效地查询数据,无论何时何地,它都被存储起来。
不变数据的问题
当然,用户很快发现,由于许多原因,数据确实需要更新。这对于事件流来说尤其如此,因为多个事件可以反映现实生活中物体的真实状态。或者网络问题或软件崩溃会导致数据延迟交付。晚到的事件需要被重新加载或回填。
公司也开始接受数据丰富化,将相关数据添加到现有表格中。最后,公司开始不得不删除客户数据,以履行消费者隐私法规,如GDPR和其"被遗忘的权利"。"
不可变的数据库制造商被迫创造变通方法,以便插入更新。一个流行的方法是由ApacheDruid和其他公司使用的一种流行方法被称为写时复制。数据仓库通常将数据加载到一个暂存区域,然后再分批摄入数据仓库,在那里进行存储、索引并为查询做好准备。如果有任何事件延迟到达,数据仓库将不得不写入新的数据,并将其保存在数据仓库中。重写临近数据以便以正确的顺序正确地存储所有数据。
在一个不可改变的数据系统中处理更新的另一个糟糕的解决方案是将原始数据保留在分区A(上面),并将晚到的数据写入不同的位置,即分区B。应用程序,而不是数据系统,将不得不跟踪所有链接但分散的记录的存储位置,以及任何由此产生的依赖关系。这个过程被称为参考完整性,必须由应用软件来实现。

这两种解决方法都有很大的问题。写时复制要求数据仓库花费大量的处理能力和时间--当更新很少的时候还可以忍受,但随着更新数量的增加,成本和速度都是无法忍受的。这就造成了严重的数据延迟,可能排除了实时分析。数据工程师还必须手动监督写入时的复制,以确保所有新旧数据被准确写入和索引。
实施参照完整性的应用程序有其自身的问题。查询必须反复检查他们是否从正确的位置提取数据,否则就有可能出现数据错误。当同一记录的更新分散在数据系统的多个地方时,尝试任何查询优化,如缓存数据,也变得更加复杂。虽然这些在节奏较慢的批处理分析系统中可能是可以容忍的,但当涉及到关键任务的实时分析时,它们是巨大的问题。
可变性有助于机器学习
在Facebook,我们建立了一个ML模型,在所有新的日历事件被创建时扫描它们,并将其存储在事件数据库中。然后,实时地,一个ML算法将检查这个事件,并决定它是否是垃圾邮件。如果它被归类为垃圾邮件,那么ML模型代码将在现有的事件记录中插入一个新字段,将其标记为垃圾邮件。因为有这么多的事件被标记并立即被删除,为了提高效率和速度,数据必须是可变的。许多现代的ML服务系统都效仿我们的例子,选择了可变的数据库。
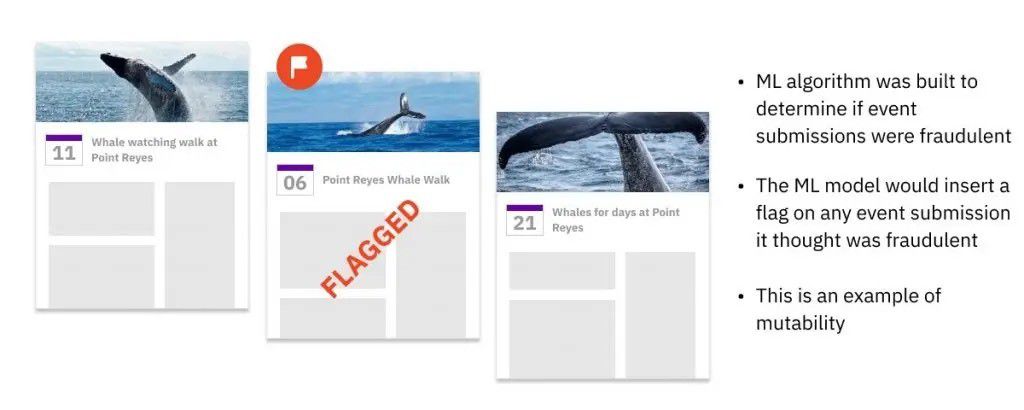
这种水平的性能在不可改变的数据中是不可能的。一个使用写时复制的数据库将很快被它必须更新的标记事件的数量所拖累。如果数据库将原始事件存储在分区A,并将标记的事件附加到分区B,这将需要额外的查询逻辑和处理能力,因为每个查询都必须合并两个分区的相关记录。这两种解决方法都会给我们的Facebook用户带来难以忍受的延迟,增加数据错误的风险,并给开发人员和/或数据工程师带来更多的工作。

可变性如何实现实时分析
在Facebook,我帮助设计了可变的分析系统,提供实时的速度、效率和可靠性。
我创立的技术之一是开源的RocksDB的高性能键值引擎,该引擎被MySQL、ApacheKafka和CockroachDB.RocksDB的数据格式是一种可变的数据格式,这意味着你可以更新、覆盖或删除一条记录中的个别字段。它也是Rockset的嵌入式存储引擎,Rockset是我创立的一个实时分析数据库,具有完全可变的索引。
通过调整开源的RocksDB,可以实现对事件和更新的SQL查询,而这些事件和更新仅在几秒钟前到达。这些查询可以在低至几百毫秒的时间内返回,即使在复杂的、临时的和高并发的情况下。RocksDB的压缩算法还能自动合并旧的和更新的数据记录,以确保查询访问最新的、正确的版本,并防止数据膨胀,以免妨碍存储效率和查询速度。
通过选择RocksDB,你可以避免不可改变的数据仓库的笨拙、昂贵和产生错误的变通方法,如写时复制和在不同分区中分散更新。
总而言之,可变性是当今实时分析的关键,因为事件流可能是不完整的或失序的。当这种情况发生时,数据库将需要纠正和回填丢失和错误的数据。为了确保高性能、低成本、无错误的查询和开发人员的效率,你的数据库必须支持可变性。


